行业资深人士:GPT-4.5 是一个奇怪的模型
2025-03-03 14:58
OpenAI 最新模型 GPT-4.5 在性能提升有限的情况下,成本却大幅增加,引发了业界对其性价比的质疑。

OpenAI 宣布推出了 GPT-4.5,公司首席执行官萨姆·阿尔特曼(Sam Altman)此前曾表示,这将是最后一个非“思维链”(Chain of Thought,CoT)模型。该公司称,新模型“并非前沿模型”,但仍然是其最大的大型语言模型(LLM),并且在计算效率上有显著提升。阿尔特曼表示,尽管 GPT-4.5 的推理方式与 OpenAI 其他新推出的 o1 或 o3-mini 模型不同,但这款新模型仍然更具人性化和深思熟虑的特点。许多行业观察人士提前接触了这款新模型,他们认为 GPT-4.5 是 OpenAI 一个有趣的举措,这也让他们调整了对该模型应达到的预期。沃顿商学院教授兼人工智能评论员埃森·莫利克(Ethan Mollick)在社交媒体上表示,GPT-4.5 是一个“非常奇特且有趣的模型”,他指出,尽管它在写作方面表现出色,但在处理复杂项目时可能会“出人意料地偷懒”。
OpenAI 联合创始人、前特斯拉人工智能负责人安德烈·卡帕西(Andrej Karpathy)表示,GPT-4.5 让他回想起 GPT-4 推出时他看到的模型潜力。在 X 平台上,卡帕西写道,使用 GPT-4.5 时,“一切都有些改进,这很棒,但这种改进并非是容易指出的具体方面。”然而,卡帕西警告说,人们不应期望该模型带来革命性的影响,因为它“在需要推理能力的关键领域(如数学、编程等)并没有推动模型能力的提升”。以下是卡帕西在 X 平台上发布的长篇帖子中对 GPT-4.5 的详细评价:“今天,OpenAI 发布了 GPT-4.5。我已经期待了大约两年,自从 GPT-4 推出以来,因为这次发布提供了一个衡量通过扩展预训练计算(即简单地训练一个更大模型)所能获得的改进斜率的定性指标。每个 0.5 的版本升级大约对应 10 倍的预训练计算量。回想一下,GPT-1 几乎无法生成连贯的文本。GPT-2 是一个令人困惑的玩具。GPT-2.5 被‘跳过’,直接升级为更有趣的 GPT-3。GPT-3.5 达到了一个临界点,足以作为产品推出,并引发了 OpenAI 的‘ChatGPT 时刻’。而 GPT-4 虽然也有所改进,但我必须说,这种改进非常微妙。我记得参加了一个黑客松,试图找到 GPT-4 明显优于 3.5 的具体提示。这些例子确实存在,但清晰且明确的‘绝对优势’案例却很难找到。一切都有些改进,但这种改进是弥散的。词汇选择更具创意,对提示中细微差别的理解有所提升,类比更有意义,模型也稍微有趣了一点,对罕见领域的知识和理解也有所改善,幻觉现象也少了一些,整体感觉更好了。这就像水涨船高的效应,一切都在不知不觉中提升了大约 20%。因此,我带着这种预期去测试 GPT-4.5,我在几天前获得了访问权限,它的预训练计算量比 GPT-4 高出 10 倍。而我感觉,我又回到了两年前的那个黑客松。一切都有些改进,这很棒,但这些改进并非是显而易见的。尽管如此,这仍然是一个非常有趣且令人兴奋的定性指标,它表明仅仅通过训练一个更大的模型,就能获得某种‘免费’的能力提升。请注意,GPT-4.5 仅通过预训练、监督微调和基于人类反馈的强化学习(RLHF)进行训练,因此它还不是一款推理模型。因此,这次模型发布并没有在需要推理能力的关键领域(如数学、编程等)推动模型能力的进步。在这些情况下,通过强化学习进行训练并获得思考能力至关重要,即使它是在较旧的基础模型上实现的(例如类似 GPT-4 的能力)。目前,最先进的模型仍然是完整的 o1。想必 OpenAI 接下来会尝试在 GPT-4.5 的基础上进一步通过强化学习进行训练,以使其具备思考能力,并推动这些领域的能力提升。然而,我们确实期望在非推理密集型任务中看到改进,我认为这些任务更多与情商(EQ)相关,例如受到世界知识、创造力、类比能力、一般理解能力、幽默感等的限制。因此,这些是我最感兴趣的能力测试领域。因此,我想在这里的 X 平台上通过一个互动的‘语言模型竞技场精简版’,结合图片和投票,以帖子的形式展示 5 个有趣 / 引人发笑的提示,来测试这些能力。遗憾的是,X 平台不允许你在单个帖子中同时包含图片和投票,因此我不得不交替发布帖子:一个帖子展示图片(提示以及来自 4 和 4.5 的两个回答),另一个帖子则是投票,人们可以投票选择哪个回答更好。8 小时后,我会揭晓哪个回答来自哪个模型。让我们看看会发生什么:)”Box 公司首席执行官阿隆·莱维(Aaron Levie)也在 X 平台上分享了他对 GPT-4.5 的看法。他认为这款模型在企业级应用中具有巨大潜力,并表示 Box 公司已经在使用 GPT-4.5 从复杂的企业内容中提取结构化数据和元数据。“人工智能的突破不断涌现。OpenAI 刚刚宣布推出 GPT-4.5,我们将在今天晚些时候通过 Box AI Studio 将其提供给 Box 客户。我们已经在 Box AI 的早期访问模式下测试了 GPT-4.5,用于高级企业非结构化数据的用例,并取得了出色的结果。通过 Box AI 的企业级评估,我们针对多种不同场景对模型进行测试,包括问答准确性、推理能力等。特别是为了探索 GPT-4.5 的能力,我们专注于一个对企业影响潜力巨大的关键领域:从复杂的企业内容中提取结构化数据,即元数据提取。在 Box,我们使用多个企业级数据集严格评估数据提取模型。其中一个关键数据集是 CUAD,它包含超过 510 份商业法律合同。在这个数据集中,Box 识别出可以从非结构化内容中提取的 17,000 个字段,并基于这些字段的单次提取对模型进行评估(这是我们最严格的测试,模型只有一次机会在单次运行中提取所有元数据,而不是多次尝试)。在我们的测试中,与 GPT-4o 相比,GPT-4.5 准确提取的字段多出了 19 个百分点,这突显了其处理复杂合同数据的更强能力。接下来,为了确保 GPT-4.5 能够应对现实世界中企业内容的需求,我们用更具挑战性的文件集对其性能进行了评估,即 Box 自己的挑战集。我们选择了一部分复杂的法律合同——那些包含多模态内容、高密度信息且长度超过 200 页的合同,来代表我们客户面临的最困难场景。在这个挑战集中,GPT-4.5 在提取关键字段的准确性上也始终优于 GPT-4o,证明了其处理复杂且微妙的法律文件的卓越能力。总体而言,我们在复杂企业数据方面看到了 GPT-4.5 的出色表现,这将为企业解锁更多用例。”尽管早期用户发现 GPT-4.5 是可以使用的尽管它有点“懒惰”,但他们对其发布提出了质疑。例如,著名的 OpenAI 批评者加里·马库斯(Gary Marcus)在 Bluesky 上称 GPT-4.5 为“毫无新意的产品”(“nothingburger”)。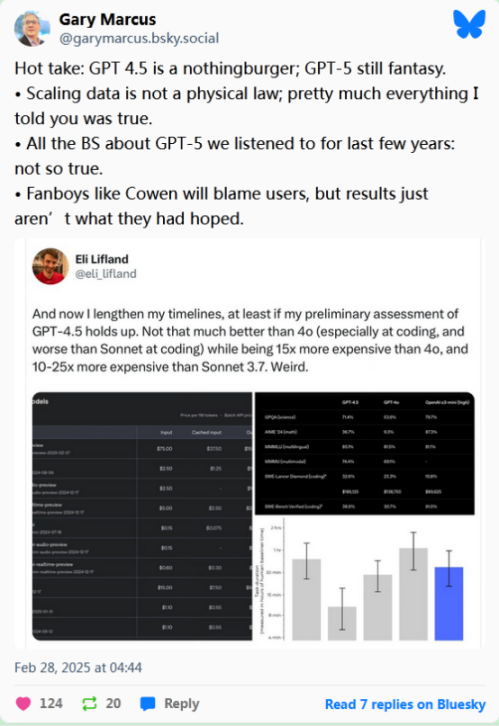
Hugging Face 首席执行官克莱门特·德朗格(Clément Delangue)评论称,GPT-4.5 的闭源特性使其显得“平平无奇”(“meh”)。然而,许多人指出,GPT-4.5 的表现并不是问题所在。相反,人们质疑的是,OpenAI 为何会发布一个使用成本如此之高、几乎令人望而却步,却又不如其其他模型强大的模型。一位用户在 X 平台上评论道:“所以你是说 GPT-4.5 的价值超过了 o1,但它的基准测试表现却不如同等级别的模型……这让人难以信服。”其他 X 用户推测,高昂的 token 成本可能是为了阻止 DeepSeek 等竞争对手“提取”4.5 模型的精华。DeepSeek 在 2024 年 1 月成为 OpenAI 的有力竞争对手,行业领导者发现 DeepSeek-R1 的推理能力与 OpenAI 的模型相当,但更具性价比。(Venture Beat)
【免责声明】市场有风险,投资需谨慎。本文不构成投资建议,用户应考虑本文中的任何意见、观点或结论是否符合其特定状况。据此投资,责任自负。



