OpenAI 发布新前沿模型 o3 和 o3-mini
2024-12-22 10:01
OpenAI 在其为期 12 天的发布活动中宣布了新一代推理系列模型 o3 及其精简版 o3-mini。

OpenAI 正在逐步邀请选定用户测试一套全新的推理模型,名为 o3 和 o3 mini,它们是本月早些时候全面发布的 o1 和 o1-mini 模型的继任者。
OpenAI o3(命名为 o3 是为了避免与电话公司 O2 产生版权问题,并且因为首席执行官萨姆·奥特曼(Sam Altman)表示公司“在命名方面确实不擅长”),在今天的“OpenAI 12 天”直播活动的最后一天宣布。奥特曼表示,这两个新模型最初将发布给选定的第三方研究人员进行安全测试,预计 o3-mini 将在 2025 年 1 月底前推出,而 o3 将在那之后不久发布。“我们认为这是人工智能下一阶段的开始,你可以使用这些模型来执行越来越复杂的任务,这些任务需要大量的推理,”奥特曼说。“在这个活动的最后一天,我们认为从一款前沿模型过渡到另一款前沿模型会很有趣。”这一宣布是在谷歌公开推出并允许公众使用其新的双子座 2.0 闪电思维模型(Gemini 2.0 Flash Thinking)的第二天发布的,这是另一个竞争对手的“推理”模型,与 OpenAI 的 o1 系列不同,它允许用户看到其“思考”过程中的步骤,这些步骤以文本项目符号的形式记录下来。双子座 2.0 闪电思维的发布以及现在 o3 的宣布表明,OpenAI 与谷歌之间,以及更广泛的人工智能模型提供商之间的竞争正在进入一个新的、激烈的阶段,因为他们提供的不仅仅是大型语言模型(LLMs)或多模态模型,还有先进的推理模型。这些模型可以更适用于科学、数学、技术、物理等领域的难题。奥特曼还表示,o3 模型在编码方面“令人难以置信”,OpenAI 分享的基准测试数据支持这一点,显示出该模型在编程任务上超越了 o1 的表现。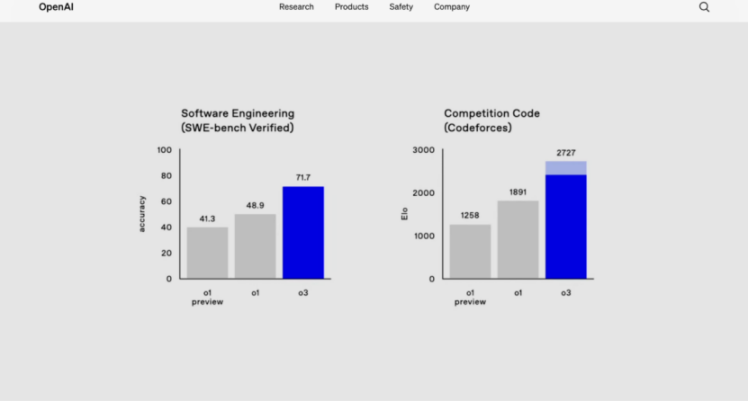
1.越编码性能:o3 在 SWE-Bench Verified 上超过 o1 22.8 个百分点,并在 Codeforces 上获得了 2727 的评分,超过了 OpenAI 首席科学家的得分 2665。2.学和科学精通:o3 在 2024 年美国数学邀请赛(AIME)上得分 96.7%,仅错过一题,并在 GPQA Diamond 上取得了 87.7% 的成绩,远远超过了人类专家的表现。3.前沿基准测试:该模型在 EpochAI 的 Frontier Math 等具有挑战性的测试中创下了新纪录,解决了 25.2% 的问题,而其他模型没有超过 2%。在 ARC-AGI 测试中,o3 的得分是 o1 的三倍,超过了 85%(由 ARC Prize 团队现场验证),代表了概念推理的里程碑。随着人工智能技术的飞速发展,OpenAI 公司最近推出了 o3 和 o3-mini 模型,标志着 AI 性能的又一次飞跃,特别是在需要高级推理和问题解决能力的领域。这些模型在编码、数学和概念基准测试中取得了卓越成绩,展现了 AI 研究的快速进步。
为了确保这些能力得到负责任的部署,OpenAI 加强了对安全和对齐的承诺,并引入了新的研究——审议式对齐技术。这项技术是使 o1 成为迄今为止最稳健和最对齐的模型的关键。审议式对齐技术将人类编写的安全规范嵌入到模型中,使模型在生成回应之前能够明确地对这些政策进行推理。这种策略旨在解决大型语言模型(LLMs)中的常见安全挑战,例如对越狱攻击的脆弱性和对良性提示的过度拒绝,通过为模型配备思维链(CoT)推理。这一过程允许模型在推理过程中动态回忆和应用安全规范。审议式对齐改进了以往的方法,如基于人类反馈的强化学习(RLHF)和宪法 AI,这些方法依赖于仅用于标签生成的安全规范,而不是将政策直接嵌入到模型中。通过对 LLMs 进行与安全相关的提示及其相关规范的微调,这种方法创建了能够进行政策驱动推理的模型,而不必严重依赖人工标记的数据。OpenAI 研究人员在一份新的非同行评审论文中分享的结果显示,这种方法增强了在安全基准测试中的表现,减少了有害输出,并确保更好地遵守内容和风格指南。关键发现强调了 o1 模型相较于前代如 GPT-4o 和其他最先进的模型的进步。审议式对齐使 o1 系列在抵抗越狱和提供安全完成的同时,最小化了对良性提示的过度拒绝。此外,该方法促进了分布外泛化,展示了在多语言和编码越狱场景中的鲁棒性。这些改进与 OpenAI 的目标一致,即随着 AI 系统能力的增长,使其更安全、更可解释。这项研究也将在对齐 o3 和 o3-mini 方面发挥关键作用,确保它们的能力既强大又负责任。如何申请测试 OpenAI 的
o3 和 o3-mini 模型
现在,OpenAI 网站开放了早期访问申请,申请截止日期为 2025 年 1 月 10 日。申请者需要填写一个在线表格,提供包括研究重点、过往经历以及之前发表的论文链接和他们在 GitHub 上的代码库链接等各类信息,并选择他们希望测试的模型 o3 或 o3-mini 以及他们计划如何使用这些模型。被选中的研究人员将获得 o3 和 o3-mini 的访问权限,以探索它们的功能并为安全评估做出贡献。不过,OpenAI 的表格提醒说,o3 模型将在几周后才能使用。
研究人员被鼓励进行严格的评估,创建高风险能力的控制演示,并在广泛使用的工具无法实现的场景中测试模型。这一举措基于公司已建立的实践,包括严格的内部安全测试、与美国和英国人工智能安全研究所等组织的合作,以及其准备框架。OpenAI 将从即日起开始滚动审查申请,并立即开始选拔。o3 和 o3-mini 的引入标志着人工智能性能的一个飞跃,特别是在需要高级推理和问题解决能力的领域。这些模型在编码、数学和概念基准测试中取得了卓越的成绩,突显了人工智能研究中正在取得的快速进展。通过邀请更广泛的研究社区参与安全测试的合作,OpenAI 旨在确保这些能力得到负责任的部署。(Venture Beat)
【免责声明】市场有风险,投资需谨慎。本文不构成投资建议,用户应考虑本文中的任何意见、观点或结论是否符合其特定状况。据此投资,责任自负。



