Anthropic 的 Claude 3.5 表明:大模型还有提升空间
Anthropic 正式发布 Claude 3.5 Sonnet,数据碾压 GPT-4o,速度也大幅提升。

据报道,在发布一个月后,一个新的大型语言模型(LLM)显然从 OpenAI 的 GPT-4手中夺走了性能桂冠。今天,由 Anthropic 发布的新的 Claude 3.5 Sonnet 聊天机器人和 LLM,在关键的第三方基准测试中超越了世界上所有其他模型。据该公司称,它不仅性能更好,而且比之前的 Claude 3 模型更快、更便宜。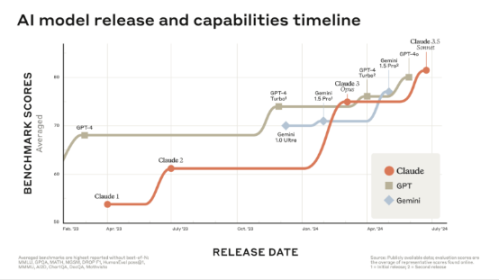
但推出一个新模型并宣称其主导地位是一回事,让用户真正体验并利用性能提升则是另一回事。
Anthropic 最新发布的 Claude 3.5 Sonnet 似乎没有这个问题。在发布后的短短几小时内,许多 AI 影响者和高级用户已经在网上分享了他们对这款新模型的积极印象,并展示了这个世界上“最智能”的大型语言模型能够完成的任务。正如企业 AI 影响者和专家艾莉·K·米勒在 X 平台上所写,Claude 3.5 Sonnet 仅凭一个截图,在不到半分钟的时间内为她创建了一个完整的可玩游戏: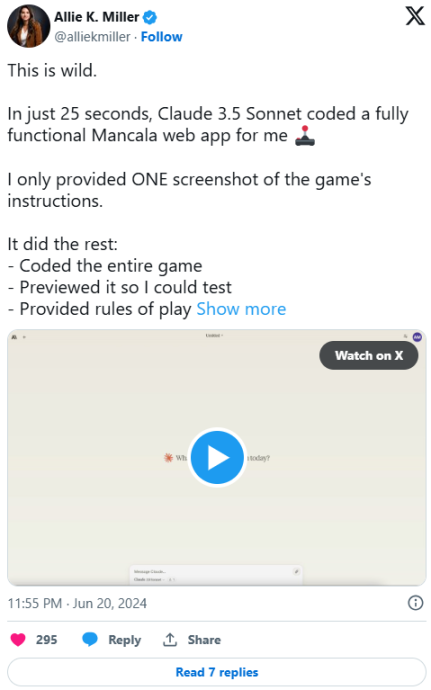
同样,信息丰富且及时的 X 账号@TestingCatalog News 展示了新推出的“Artifacts” playground——该平台与 Claude 3.5 Sonnet 同时亮相,实际上展示了聊天机器人界面旁边的交互输出视图——可以执行 Claude 3.5 Sonnet 构建的真实可用的网页表单代码。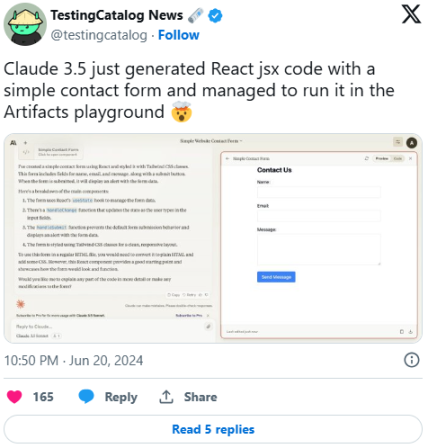
它甚至能够重现 1995 年经典电影《黑客帝国》(Hackers)中的影像: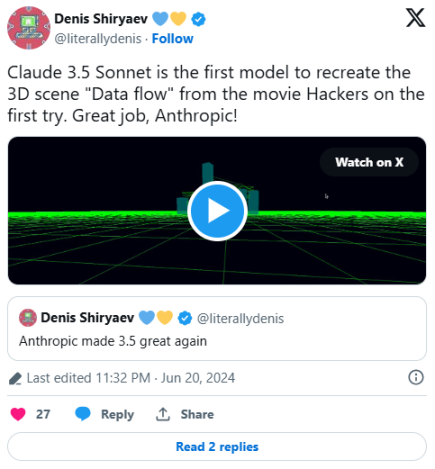
企业 AI 图像生成初创公司 EverArt 的创始人彼得罗·施拉诺在 X 平台上写道,将 Claude 3.5 Sonnet 与另一款工具 Maestro 结合使用,显示出“通用人工智能的火花?”
Anthropic 员工为
Claude 3.5 Sonnet 站台
尽管显然存在偏见,Anthropic 开发者关系团队负责人亚历克斯·艾伯特在 X 平台上发了一条帖子,强调 Claude 3.5 Sonnet “在编程和自主修复拉取请求方面开始变得非常出色”,甚至表示:“很明显,再过一年,大量代码将由大型语言模型编写。”
同样,Anthropic 的技术人员玛吉·沃在 X 平台上发帖称,Claude 3.5 Sonnet 现在能完成“我一半的工作……我对此感到非常高兴。”
其他人则指出,现在 Claude 3.5 Sonnet 已经超越了 OpenAI 的 GPT-4o,并且以类似的价格提供,后者公司面临着继续证明其模型是正确选择的新的压力。宾夕法尼亚大学沃顿商学院教授兼 AI 推动者伊桑·莫利克将 Artifacts 功能与 OpenAI GPT-4 的“简化版 Code Interpreter”进行了比较。
X 用户@kimmonismus 更进一步,表示 OpenAI 将“错过通用人工智能(AGI)”,即公司宣称的在大多数具有经济价值的工作中表现优于人类的 AI 模型目标。他们抨击公司宣布了尚未推出的 GPT-4o 的附加功能,包括新的语音模式。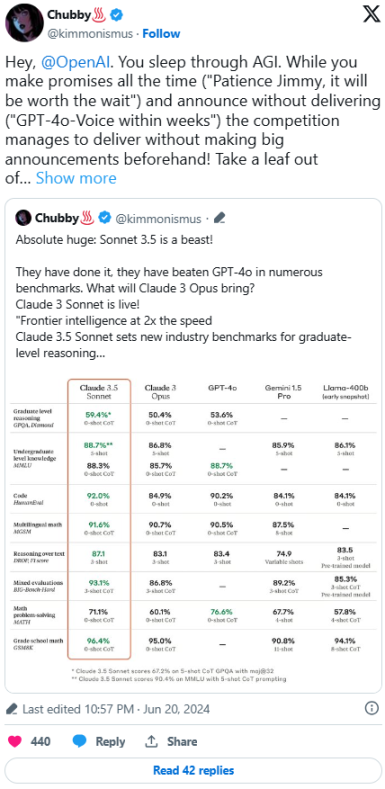
尽管在 X 平台上备受赞誉,但也有人指出,Claude 3.5 Sonnet 在一些看似简单的认知任务上仍然存在困难,这些任务是人类相对容易完成的,比如玩“井字棋”。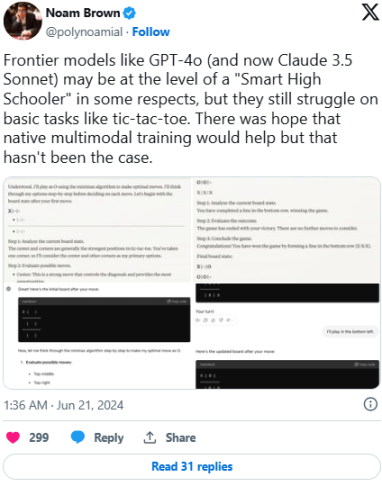
同样,科技记者蒂莫西·B·李,在 X 平台上以@binarybits 为名,指出它“有时仍会犯愚蠢的错误”。他发布了一张截图,展示了一个简单的数学文字问题的答案:哪个更值钱:100 个便士还是 3 个 25 美分硬币?Claude 3.5 Sonnet 最初回答是 3 个 25 美分硬币。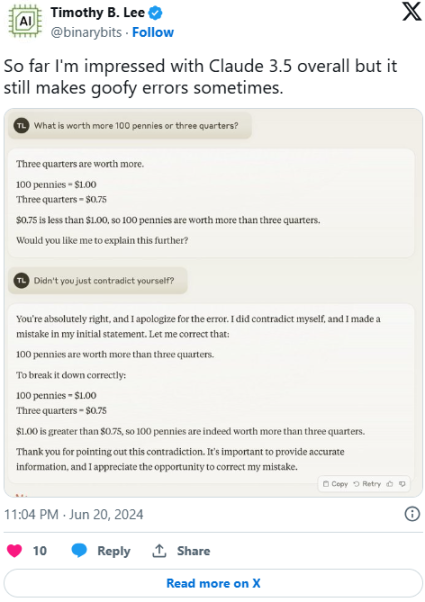
尽管目前存在这些较小的问题,Claude 3.5 Sonnet 仍然是 Anthropic 和大型语言模型(LLM)的一个巨大飞跃,并表明各个 AI 模型制造商的性能提升在当前可用计算资源(如 GPU)水平上肯定没有放缓。(VentureBeat)
【免责声明】市场有风险,投资需谨慎。本文不构成投资建议,用户应考虑本文中的任何意见、观点或结论是否符合其特定状况。据此投资,责任自负。



